[첨단 헬로티]
복잡한 이미지 처리 작업을 수행하는 신경망
신경망을 이용한 딥 러닝은 최종 이미지 품질뿐만 아니라 분류 및 분석 결과와 관련해서도 여러 가지 큰 이점을 제공하므로 이미지 처리의 미래에 큰 영향을 미칠 것이다.

대부분의 일반적인 이미지 인식 작업은 소규모 신경망으로도 충분하기 때문에 FPGA 같은 프로세서를 나선구조신경망(convolutional neural networks, CNN)에 대해 효과적으로 구현할 수 있다. 이로 인해 기존의 분류 작업 외에 훨씬 광범위한 분야에서 활용이 가능해지고, 내장 이미지 인식 시스템 내에서도 효율적으로 사용할 수 있게 된다.
▲ (출처:Silicon Software GmbH)
기존 이미지 처리는 테스트 대상이 기형이거나, 부적합한 조명 환경이나 렌즈 왜곡으로 인해 불규칙한 모양 또는 큰 대상 변형이 나타나는 경우 성능적 한계에 도달한다. 이러한 예처럼 이미지 획득을 위한 프레임워크 조건을 제어하지 못한다면 특징 묘사를 위한 개별 알고리즘도 대개 소용이 없다.
반면에 CNN은 자체 훈련 방식을 통해 특징을 정의하며 수학적 모델을 사용하지 않는다. 따라서 반사면, 이동 중인 대상, 얼굴 감지, 로봇 공학 등과 같은 까다로운 환경에서 이미지를 캡처하고 분석할 수 있으며, 사전 처리에서 분류 결과로 이미지 데이터를 바로 간편하게 분류할 수 있다. 이는 많은 작업에서 요구되는 기능이다. 하지만 CNN은 대상의 정확한 위치 파악 등을 비롯하여 기존 이미지 처리의 모든 영역에서 사용할 수는 없다. 이를 위해서는 더욱 새롭고 진보된 CNN의 개발이 필요하다.

▲ 감지한 오류 등급(왼쪽에서 오른쪽 방향): 롤드인 스케일, 반점, 잔균열,
움푹 패인 표면, 이물질 포함, 긁힘 (출처: NEUSurface Defect Database)
CNN 최적화를 통해 이미지 인식 기술 가속화
지난 수년간 CNN을 실제로 활용하면서 여러 가지 수학적 가정과 단순화 기법(예: 풀링, ReLu, 오버피팅 방지 등)을 발견했으며, 이를 통해 연산 비용을 줄인 결과 더욱 깊은 신경망 층을 구현할 수 있게 되었다. 동일한 감지 속도로 이미지 깊이를 줄이고 해당 알고리즘을 최적화함으로써 CNN을 크게 가속화할 수 있어서 이미지 처리에 아주 이상적이다. 또한 이동 불변(shift-invariant)이고 부분적으로 확장 불변(scale-invariant)이기 때문에 동일한 망 구조를 다양한 이미지 해상도에 사용할 수 있다. 대부분의 이미지 처리 작업은 소규모 신경망으로도 충분한 경우가 많다.
높은 수준의 병렬 처리 성능을 자랑하는 신경망은 특히 FPGA(Field Programmable Gate Array)에 매우 적합하다. CNN 역시 이 프로세서를 이용하여 고해상도 이미지를 실시간으로 분석하고 분류한다.
머신비전의 경우 FPGA는 이미지 처리 작업을 대폭 가속화하기 때문에 확정적 지연으로 실시간 처리가 가능하다. 지금까지는 프로그래밍 작업이 많이 필요하고 FPGA에 이용 가능한 리소스가 부족해서 효율적으로 사용하기가 어려웠다. 이제는 알고리즘을 단순화한 덕분에 FPGA의 빠른 처리 속도를 통해 효율적으로 망을 만들 수 있다.
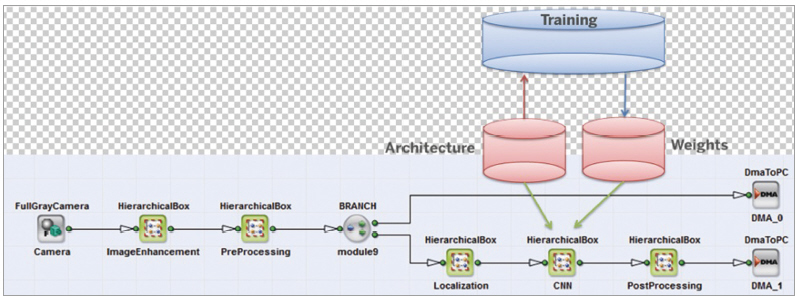
▲ VisualApplets에 통합된 CNN (출처: Silicon Software GmbH)
새로운 CNN 연산자 및 프레임 그래버 개발
FPGA 하드웨어 플랫폼에 CNN을 구현하기 위해 VisualApplets 그래픽 환경을 사용할 수 있다. VisualApplets의 CNN 연산자를 이용하면 사용자가 하드웨어 프로그래밍 경험 없이도 단시간에 다양한 FPGA 애플리케이션 디자인을 만들고 합성할 수 있다. 훈련 과정에서 확인한 가중치 및 변화율 매개변수를 CNN 연산자로 전달하면 FPGA 디자인이 특정 작업별로 구성된다.
이러한 연산자들을 VisualApplets 플로 다이어그램 디자인에 통합하여 디지털 카메라를 이미지 입력 장치로 사용하고 추가 이미지 처리 연산자를 이미지 처리 최적화에 사용할 수 있다.

▲ Visual Applets으로 구현한 금속 표면의 결함 분류 CNN 데모기
(출처: Silicon Software GmbH)
복잡한 CNN 작업을 위해 매우 큰 신경망을 구현할 수 있도록 microEnable 마라톤 시리즈의 최신 프로그래밍 가능 프레임 그래버가 출시될 예정이다. 기존 플래그십 마라톤 시리즈보다 FPGA 리소스가 2.5배 더 많으며, 1GB/초 이상의 CNN 대역폭을 제공하기 때문에 신경망에 매우 적합할 것으로 예상된다.
CNN은 프레임 그래버의 FPGA뿐만 아니라 VisualApplets 호환 카메라 및 이미지 인식 센서에도 사용할 수 있다. FPGA은 GPU보다 에너지 효율이 최대 10배 더 높기 때문에 CNN 기반 작업은 적은 열배출이 요구되는 모바일 로봇 또는 내장 시스템에서 아주 효과적으로 구현될 수 있다.
향후에는 새로 개발된 특수 프로세서를 사용하여 더욱 다양하고 복잡한 작업에 신경망을 활용할 수 있을 전망이다. 새로운 하드웨어 및 소프트웨어 솔루션을 개발하고 연구 결과를 교환하기 위해 독일 카를스루에 공과대학(Karlsruhe Institute of Technology, KIT) 산하 산업정보기술 연구소(Institute for Industrial Information Technology, IIIT)의 Michael Heizmann 교수와의 협업을 통해 FPGA 기반 '산업용 머신 러닝' 프로젝트를 진행하고 있다. 이를 통해 향후 새로운 기술적 진전을 이룰 것으로 기대된다.
까다로운 환경 조건에서 정확하게 감지되는 결함의 비율을 판단하기 위해 1,800개의 반사 금속판 이미지가 포함된 신경망을 여섯 가지의 결함 등급을 정의하도록 훈련시켰다. 큰 긁힘과 작은 잔균열이 한데 뒤섞여 있는 데다가, 조명과 소재 차이로 인해 표면의 회색톤이 다르게 보여서 기존 이미지 처리 시스템으로는 표면 분석이 거의 불가능했다.
테스트 결과에 따르면 신경망은 다양한 결함을 평균 97.4%의 정확도로 확실하게 분류했다.
이는 기존 방식보다 훨씬 높은 수치이다. 이 작업에서 데이터 처리 속도는 400MB/초였다. 그에 비해 CPU 기반 소프트웨어 솔루션의 속도는 평균 20MB/초에 불과했다.
FPGA 프로세서 기술을 활용하는 딥 러닝 구현은 중요한 진전이며, 특히 이미지 처리 작업에 매우 적합하다.
하지만 이러한 방식은 확정적이고 알고리즘적으로 검증이 가능해야 하기 때문에 모든 이미지 처리 분야에 적용하기는 어렵다. 또한 오류로 식별된 영역을 문서화하는 옵션과 세분화 및 저장 기능이 아직까지 구현되지 않았다.
향후 전망: 지금까지 CNN의 훈련과 작업은 별도의 프로세스로 진행되었다. 미래에 더 높은 리소스를 보유하고 강력한 ARM/CPU 및 GPU 코어를 사용하는 차세대 FPGA가 개발되면 새롭게 획득하는 이미지 자료에 대해 실시간 훈련이 가능해지고, 감지율은 대폭 상승하고 학습 프로세스는 단순해질 것이다.




